最近几天都没有时间写博客了,其实也没有什么好说的。
连续两周加班,效率超级低。天天一点屁事还要做的很晚,关键是对系统实在是不熟悉。真的得花点时间在PIKE上了。
要不然,真的每次做一点界面就是一天,还各种BUG。
总结一下最近的关键问题:写代码命名不规范,效率低,代码需要多多进行抽象,封装。能复用的尽量多复用。
因为这段时间敲代码,感觉一直都是停留在很低的一个层次,比CV高一点吧。所以感觉到Java基础还是不扎实。
真觉得自己心比天高,想学这个,想学那个。结果自己吃饭的本事还学的不扎实。
所以打算今后一段之间,空闲的时候,恶补一下Java基础吧。
我总是这样。说出的话与做出的事总有差别。尽量规正吧。
言归正传,私以为,当下很多博客都有CV之嫌,那句话怎么说的,我们不生产代码,我们只是代码的搬运工
昨天看源码的时候,突然看到了一个经常会被我忽略的东西,serialization序列化。
细想一下,又想不起来了序列化和反序列化的作用。
什么是序列化?
从广义上来说,Java序列化是为了持久化存储对象状态的一种方式。它指的是能够把堆内存中的Java对象数据,通过某种方式存储到磁盘文件中或者传递给其他网络节点(在网络上传输)。
反序列化就是上述步骤相反的过程,把磁盘文件中的对象数据或者把网络节点上的对象数据,恢复成Java对象的过程。
为什么要进行序列化?
-
在分布式系统中,需要共享数据的实体对象都需要进行序列化,因为此时需要将对象在网络上进行传输,需要将对象转换成二进制的形式。 在Java中,想要进行序列化,就必须实现Serializable接口,这个接口没有任何的方法,它就是一个标志接口,只要实现了这个接口,那么你就可以开始你的表演了,序列化。
-
服务钝化: 听说过Session钝化和活化么? 其实不就是把不怎么使用的对象由内存堆中序列化到磁盘空间上。 这整个过程就是将Java对象,转换成二进制文件。如果序列化之后,还需要使用这个对象,先会从内存堆中去找,如果找不到,就再会去相应的磁盘空间中去找,如果找到了,就会将其由二进制文件再次转换成Java对象。
在Java中,提供了序列化以及反序列化的类: java.io.ObjectOutputStream 以及 java.io.ObjectInputStream

下面,看一个序列化的例子,这是一个普通的不能再普通的例子了:
public class ObjectOutputSteamDemo {
public static void main(String[] args) {
File serialization = new File("./serizaliable.txt");
serializationOperation(serialization);
}
/**
*
* method desc 该方法用于进行序列化操作,将Java对象通过流的方式存储在磁盘文件上
*
* @param serialization:
* 存放对象数据的文件
*/
private static void serializationOperation(File serialization) {
ObjectOutputStream outputStream = null;
try {
outputStream = new ObjectOutputStream(new FileOutputStream(serialization));
outputStream.writeObject(new Programmer("xiaoxiong", "12345", 18));
outputStream.flush();
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
为了方便操作,创建了一个实体对象,用于供ObjectOutputSteam进行writeObjec操作:
public class Programmer {
private String name;
private String password;
private int age;
public Programmer(String name, String password, int age) {
super();
this.name = name;
this.password = password;
this.age = age;
}
@Override
public String toString() {
return "Programmer [name=" + name + ", password=" + password + ", age=" + age + "]";
}
}
自行导入类,编译运行,你会发现得到了一个运行时异常错误:
java.io.NotSerializableException: com.hardstudy.entity.Programmer
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1184)
at java.io.ObjectOutputStream.writeObject(ObjectOutputStream.java:348)
at com.hardstudy.io.serialization.ObjectOutputSteamDemo.serializationOperation(ObjectOutputSteamDemo.java:39)
at com.hardstudy.io.serialization.ObjectOutputSteamDemo.main(ObjectOutputSteamDemo.java:24)
这个异常是怎么出现的呢? debug一下就不难发现,出现这个异常的原因是Programmer类没有实现Serializable接口。
稍微变化一下,给我们的实体类增加一个Serializable接口,再次运行,你会发现,成功运行并将内容写入磁盘文件serialization.txt中。不过都是写乱码,这是供反序列化的时候读取的。
下面再看看怎么把数据从磁盘中读取出来:
/**
*
* method desc 反序列化,将磁盘文件中的内容读取成Java对象
*
* @param serialization
*/
private static void deserializationOperation(File serialization) {
try {
ObjectInputStream inputStream = new ObjectInputStream(new FileInputStream(serialization));
Programmer programmer = (Programmer) inputStream.readObject();
System.out.println(programmer);
inputStream.close();
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
其实很好理解,序列化以及反序列化就是两个相反的行为,一个是将内容从程序中读到外部,且不管是外部指的是磁盘文件还是其他不同的网段上,这在Java中就需要使用输出流。而反序列化则是将外部的内容读取成Java内存(内部)的对象,因此使用输入流。
总结一下: 需要做序列化的对象的类必须要实现Serializable这个标志接口,底层它会进行判断,this.getClass().isAssignableFrom(Serializable.class); (还有一个instanceOf 也可以用来判断) 如果为真,则会进行序列化操作。 这也就是这个标志接口的作用。
Java中大部分类都实现了Serializable,如,String,Integer这类经常用来传递数据的类。
transient关键字
在Java的Serializable接口的API中,明确的声明了一下几点:
The readObject method is responsible for reading from the stream and restoring the classes fields. It may call in.defaultReadObject to invoke the default mechanism for restoring the object's non-static and non-transient fields.
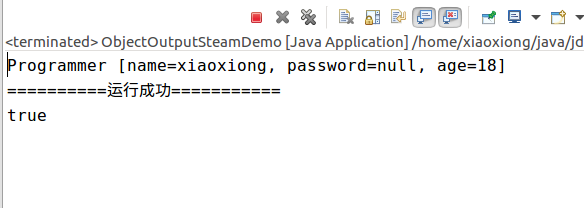
第一点,ObjectInputStream的readObject方法将只会读取并存储那些非静态以及非瞬时的属性,这其实是非常有效的,比如,我们并不像把Password这种数据直接反序列化出来,那么此时的transient就非常有效。
下面,把Programmer类的Password改成transient形式:
private String name;
transient private String password;
private int age;
再次编译的时候,就会发现一个错误:
java.io.InvalidClassException: com.hardstudy.entity.Programmer; local class incompatible: stream classdesc serialVersionUID = 6334356052556574577, local class serialVersionUID = -8942116313638965447
这是为什么呢?看看Serializable接口的API
反序列化Java对象时必须提供对象的class文件,问题是,随着项目的升级,系统的class文件也会随之变化(增加一个字段或者删除一个字段),如何保证两个class文件的兼容性呢? Java通过serialVersionUID序列化版本号来判断字节码是否发生变化。
如果没有显示的定义序列化版本号,那么JVM会自动根据类相关信息为我们创建出来,而修改之后的类往往得到其他的版本号,因此,在反序列化的时候,两个版本匹配不了,就会出现java.io.InvalidClassException异常。
注意,这里需要明白,在序列化操作的时候,JVM已经为我们创建了版本号,并且帮我们已经放进了文件当中去,这就是说,这文件,只有我这个版本的才能反序列化出来,其他的没门!!! 那么下次变化了文件,JVM又帮我们生成其他一个不同的版本号,拿着这个版本号去反序列原先那个磁盘文件(假设), 那不就是相当于拿你家钥匙开别家的门吗?
所以,都加上一个Long的序列号,无论我怎么改,我家的钥匙永远都能开自己家的门。
因此,最好建议在实现了Serializable接口之后,提供一个固定的UID,这样就可以防止出现一系列的问题。
private static final long serialVersionUID = 1L; // 加入序列号
private String name;
transient private String password;
private int age;
解决了这个异常,继续编译,你就会发现,在反序列化的时候,这个被transient修饰的属性隐藏掉了。
这就是序列化与反序列化的一些介绍,内容其实不难,了解序列化的作用,为了更好的使用对象(将对象转换成二进制)以及对象的钝化(有效减少堆内存),还有序列号版本问题以及transient关键字的使用,有效避免一些字段的序列化操作。